-
DeepSeek如何赋能科普内容创作?一文解锁N种方法
2025-02-25 10:43:26
-
DeepSeek公司背景与发展
DeepSeek于2023年成立,其母公司幻方量化在量化投资领域成绩斐然,是国内顶尖的量化投资公司,管理规模曾一度突破千亿大关。2020年3月,幻方量化建立萤火一号算力集群,紧接着在2021年建立萤火二号,二者共同构成了当时亚洲规模最大的私有化AI算力池,拥有近万张A100 卡。当时,幻方量化出于自身量化投资对算力的需求建立此算力池,同时面向公众开放使用。这一举措为后来大模型的发展奠定了坚实基础,也展现了幻方量化在技术布局上的前瞻性。

DeepSeek模型发展历程
DeepSeek在模型研发上稳步推进,2024年初推出首个大模型版本,起初在行业内并未引起较大轰动。然而,2024年5月推出的V2版本开始崭露头角,性能对标GPT-4,而价格仅为GPT-4的百分之一。在国外学术圈和工业圈,它早早受到关注,特别是在代码开发领域表现突出,成为国外众多AI Coding软件中唯一集成的国产大模型。去年年底推出的V3和R1版本(běn)更(gèng)是(shì)引(yǐn)起(qǐ)了(le)国(guó)内(nèi)外(wài)的(de)广(guǎng)泛(fàn)关注(zhù),其(qí)模(mó)型(xíng)性(xìng)能(néng)对(duì)标(biāo)国(guó)外(wài)最(zuì)顶(dǐng)尖(jiān)的(de)OpenAI-o1模(mó)型(xíng),充(chōng)分(fēn)展(zhǎn)示(shì)了(le)DeepSeek在(zài)技(jì)术(shù)研(yán)发(fā)上(shàng)的(de)实(shí)力(lì)。
DeepSeek技(jì)术(shù)优(yōu)势(shì)剖(pōu)析(xī)
基(jī)于(yú)强(qiáng)化(huà)学(xué)习(xí)的(de)训(xun)练(liàn)方(fāng)式(shì)
DeepSeek-R1的(de)Zero版(bǎn)本(běn)基(jī)于(yú)大(dà)规(guī)模(mó)强(qiáng)化(huà)学(xué)习(xí)进(jìn)行(xíng)训(xun)练(liàn),抛(pāo)弃(qì)了(le)传(chuán)统(tǒng)的(de)基(jī)于(yú)人(rén)类(lèi)标(biāo)注(zhù)反(fǎn)馈(kuì)数(shù)据(jù)训(xun)练(liàn)的(de)奖(jiǎng)励(lì)模(mó)型(xíng),选(xuǎn)择(zé)了(le)客(kè)观(guān)评(píng)价(jià)指(zhǐ)标(biāo)作(zuò)为(wèi)奖(jiǎng)励(lì)模(mó)型(xíng)。这(zhè)种(zhǒng)奖(jiǎng)励(lì)模(mó)型(xíng)主要(yào)基(jī)于(yú)两(liǎng)个(gè)核(hé)心(xīn)要(yào)点(diǎn):一(yī)是(shì)回(huí)答(dá)的(de)答(dá)案(àn)是(shì)否(fǒu)准(zhǔn)确(què),即(jí)是(shì)否(fǒu)可(kě)通(tōng)过(guò)计(jì)算(suàn)规(guī)则(zé)进(jìn)行(xíng)检(jiǎn)验(yàn);二(èr)是(shì)答(dá)案(àn)格(gé)式(shì)是(shì)否(fǒu)符(fú)合(hé)要(yào)求(qiú),即(jí)是(shì)否(fǒu)包(bāo)含(hán)了(le)思(sī)考(kǎo)的(de)过(guò)程(chéng)。以(yǐ)回(huí)答(dá)数(shù)学(xué)问(wèn)题(tí)为(wèi)例(lì),若(ruò)模(mó)型(xíng)简(jiǎn)单(dān)回(huí)答(dá)正(zhèng)确(què)记(jì)1分(fēn),若(ruò)通(tōng)过(guò)逻(luó)辑(ji)推(tuī)理(lǐ)得(de)出(chū)正(zhèng)确(què)答(dá)案(àn)则(zé)记(jì)2分(fēn),答(dá)案(àn)错(cuò)误(wù)记(jì)0分(fēn);在(zài)代(dài)码(mǎ)生(shēng)成(chéng)任(rèn)务(wu)中,通过(guò)编(biān)译(yì)器(qì)运(yùn)行(xíng)结(jié)果(guǒ)判(pàn)断(duàn),符(fú)合(hé)预(yù)期(qī)记(jì)1分(fēn),编(biān)译(yì)失(shī)败(bài)或(huò)结(jié)果(guǒ)错(cuò)误(wù)记(jì)0分(fēn),有(yǒu)思(sī)考(kǎo)过(guò)程(chéng)会(huì)额(é)外(wài)加(jiā)分(fēn)。与(yǔ)传(chuán)统(tǒng)依(yī)赖(lài)人(rén)类(lèi)标(biāo)注(zhù)的(de)方(fāng)式(shì)相(xiāng)比,DeepSeek的评价方式更加客观,有效避免了人类标注存在的效率和准确率问题,同时也规避了人工反馈带来的主观和价值观因素影响。

创新的模型架构
在模型架构方面,DeepSeek有诸多创新。DeepSeek采取目前流行的混合专家(MoE)架构,MoE借鉴了人类大脑的工作原理。大脑的不同区域负责不同功能,如前额叶负责逻辑推理,颞叶中的梭状回(huí)面(miàn)孔(kǒng)区(qū)负(fù)责(zé)人(rén)脸(liǎn)识(shi)别(bié)、而海马体负责记忆等。MoE架构下参数量虽大,但特定任务仅由特定的一小部分参数处理,这极大地降低了计算消耗,同时也便于对参数权重进行定向优化。此外,DeepSeek自主创新的MLA模型通过算法调整,减少了推理过程的KV Cache,降低了显存消耗,进而提高了推理效率。这两种架构的结合,为DeepSeek的高性能表现提供了有力支持。
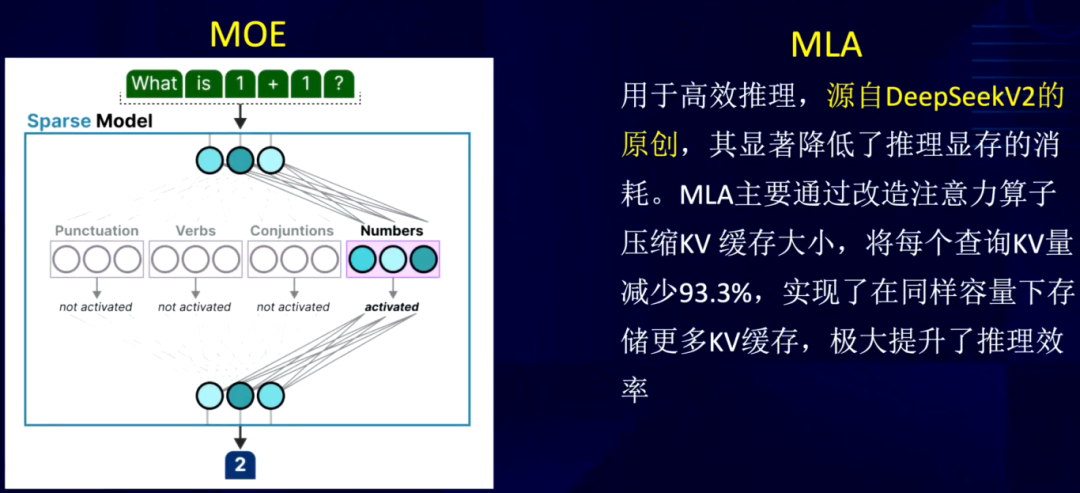
软硬件协同优化策略
虽然DeepSeek很早就建设了万卡集群,但是与国外同行相比,规模依然不足。面对算力资源的限制,DeepSeek采用了精细的调度算法,压榨硬件的每一分算力。传统方式在训练时,参数权重更新需一层一层按顺序处理,存在排队等待的情况,导致算力利用率不高。而DeepSeek的DualPipe调度算法类似于流程优化,通过合理安排前向过程、后向过程以及层间通讯,使有前后依赖的任务紧密协作,从而在最短时间内完成一轮迭代训练。这种软硬件协同的方式,在国产GPU算力与英伟达GPU存在差距的情况下,通过软件优化弥补了硬件的不足,为AI产业的发展开辟了新的路径。

DeepSeek的特点
DeepSeek的以下几个特点,使其成为独树一帜的标杆。
首先,其训练成本大幅下降,外媒(méi)报(bào)道(dào)仅(jǐn)需(xū)几(jǐ)百(bǎi)万(wàn)美(měi)元(yuán),与(yǔ)之(zhī)前(qián)动(dòng)辄(zhé)上(shàng)亿(yì)的(de)训(xun)练(liàn)成本相比成本显著降低。同时,通过蒸馏DeepSeek生成高质量的推理数据,再利用这些数据微调像千问、Llama等开源小模型,用极低成本大幅提升了这些小模型的性能。
其次,DeepSeek将最大规模的671B模型参数完全公开,且开源协议非常宽松,允许自由修改、复制和商业化,这消除了企业在数据安全方面的顾虑,使企业能够放心地在自己的环境内部署(shǔ)私(sī)有(yǒu)化(huà)版本,将企业内部的文档、技术资料甚至财务数据用于大模型的问答和应用,扫除了大模型应用的最大障碍。
因此,DeepSeek彻底颠覆了AI产业原有的商业模式,原来通过商用模型部署的业务模式因DeepSeek的出现而发生巨大改变。

DeepSeek使用经验分享
访问与替代方案
目前,DeepSeek提供了官网和APP供用户使用,但是因用户量爆棚,在使用时可能会出现不稳定的情况。在这种情况下,有一些替代方(fāng)案(àn)可(kě)供(gōng)选(xuǎn)择(zé),如(rú)腾(téng)讯(xùn)元(yuán)宝(bǎo)和(hé) 纳(nà)米(mǐ)搜(sōu)索(suǒ)等(děng)。这(zhè)些(xiē)平(píng)台(tái)支(zhī)持(chí)全尺(chǐ)寸(cùn)模(mó)型(xíng)的(de)问(wèn)答(dá)功(gōng)能(néng),还(hái)具(jù)备(bèi)联(lián)网(wǎng)搜(sōu)索(suǒ)和(hé)文件(jiàn)上(shàng)传(chuán)等(děng)功(gōng)能(néng),在(zài)DeepSeek官(guān)网(wǎng)不(bù)稳(wěn)定(dìng)时(shí)能(néng)为用户提供备用方案。
使用技巧与注意事项
使用DeepSeek时,打开“深度思考”开关至关重要,因为该开关关闭时使用的是V3非推理模型,而打开后则调用R1推理模型,能获得更强大的功能。在提问方式上,相比以往复杂的提示词工程,DeepSeek推(tuī)荐(jiàn)使(shǐ)用(yòng)更(gèng)自(zì)然(rán)的(de)表(biǎo)达(dá)方式。用户只需专注描述问题的背景信息、明确自己的目标以及添加风格(gé)提(tí)示(shì)等(děng),例(lì)如(rú)要(yào)求(qiú)“面(miàn)向(xiàng)初(chū)中(zhōng)生(shēng)以(yǐ)鲁(lǔ)迅(xùn)风(fēng)格(gé)写(xiě)一(yī)篇(piān)食(shí)品(pǐn)类(lèi)科(kē)普(pǔ)文章(zhāng)”。此(cǐ)外(wài),强(qiáng)烈(liè)推(tuī)荐(jiàn)用(yòng)户(hù)阅(yuè)读(dú)清(qīng)华(huá)大(dà)学(xué)出(chū)版(bǎn)的(de)关于DeepSeek使用介绍的 PPT,其中详细介绍了向DeepSeek提问的技巧,有助于用户更好地与模型进行交互。

如何将DeepSeek用于科普创作?
科普主题发掘
DeepSeek在科普主题发掘方面具有很大的潜力。它可以在特定领域,如前沿科技、城市生活常识(shi)、当(dāng)下(xià)流行的伪科学等方向,为创作者提供科普主题。同时,还能根据不同的受众群体,生成相应的主题。例如,针对60~70岁的老人,DeepSeek会提供(gōng)围(wéi)绕(rào)健(jiàn)康(kāng)管(guǎn)理(lǐ)方(fāng)面(miàn)的(de)三(sān)高(gāo)管(guǎn)理(lǐ)、科(kē)学(xué)饮(yǐn)食(shí),以(yǐ)及(jí)退(tuì)休(xiū)后(hòu)的(de)心(xīn)理(lǐ)健(jiàn)康(kāng)指(zhǐ)南(nán)等(děng)主题(tí);而(ér)针(zhēn)对(duì)青(qīng)少年破除伪科学的需求,DeepSeek会提供星座算命、手机致癌、外星人绑架等新奇有趣的主题。此外,结合近期热点新闻,DeepSeek能从热点话题中筛选出有价值的科普主题,如根据近期小行星撞地球的热点话题,为科普创作提供灵感。
科普内容生成
基于给定的科普主题,DeepSeek能够为不同受众生成针对性的科普内容。以人造太阳的科普为例,当要求为小学三年级学生创作科普文章时,它会避免使用专业术语,尽量用浅显易懂的语言描述人造太阳的价值和功能;而当为高中三年级学生创作时,则会包含科学专业术语和相关数据,适合高中学生作为课外拓展阅读。DeepSeek还可以生成短视频脚本,为科普短视频的制作提供便利。同时,在科普分级读物方面,它具有生成不同难度文章的能力,通过难度设定可(kě)以(yǐ)精(jīng)确(què)匹(pǐ)配(pèi)不(bù)同(tóng)阅(yuè)读(dú)水(shuǐ)平(píng)的(de)需(xū)求(qiú),这(zhè)对(duì)于(yú)中(zhōng)文科(kē)普(pǔ)分(fēn)级(jí)读(dú)物(wù)的(de)发(fā)展(zhǎn)具(jù)有重要意义。

此外,在科普访谈方面,DeepSeek可以根据访谈对象和主题,结合互联网上的相关材料,生成定制化的访谈提纲。访谈结束后,还能根据访谈文字稿辅助生成总结文章,提高工作效率。在处理国外前沿论(lùn)文时(shí),DeepSeek可以将论文内容转化为有趣的科普文章(zhāng),在(zài)内容风格上并非机械解读,而是结合科普宣(xuān)传的需求,吸引读者的注意力。
拓展应用场景
DeepSeek结合其他技术,能够拓展科普内容创作的边界。例如,结合简易AI自动化匹配视频素材并进行剪辑,再结合文本生成语音(TTS)技术,可以制作完整的科普短视频;结合豆包进行文本生成,实现图文混排,使科普内容更具吸引力;结合Kimi等相关工具可以制作科普PPT,用于展示科普知识;结合数字人技术生成科普数字人,为中小学生或特定用户群体介绍科普内容,这种应用在科普基地、博物馆等场所具有广阔的发展空间。

AI时代不缺好答案,而是缺好问题。提出好问题可能是人们未来需要学习、提高的重要素质。期待人工智能未来在科普内容创作领域发挥更大的价值,助力全民科学素质水平提升。
(作者:董霖,浙江省科普联合会副会长、每日互动创始团队成员、首席数据官)
本文根据浙江省科普联合会周四夜学内容整理

